科技成果简介
成果名称:
基于深度学习的中文自然语言处理以及基础资源
项目负责人:
陈清财
所属领域:
自然语言处理、人工智能
成果简介:
在国务院发布的《新一代人工智能发展规划》中,“建立数据驱动、以自然语言理解为核心的认知计算模型”被列为新一代人工智能基础理论体系的重要组成部分。因此,《规划》中将建设面向人工智能的公共数据资源库、标准测试数据集作为基础支撑平台的重要内容,突出了公共数据资源构建的对人工智能发展的重要意义。
大规模标准数据集则是数据驱动的自然语言处理技术发展的重要支撑,大规模中文资源的缺乏,严重制约了中文处理技术的发展。为此,经过多年努力,团队研发了从互联网中构建了大规模高质量生成式文摘库和语句意图匹配库的方法,并在国际顶会上发布了3个高质量的大规模中文标准语料库,填补了相关任务中文国际标准语料库的空白,这些语料库已经被收入百度“千言”计划标准评测中,3个语料库合计近400家国内外机构申请使用。在2021年,BQ金融领域问题匹配数据集、LCQMC通用领域问题匹配数据集共应用于「千言数据集:文本相似度」、「千言数据集:问题匹配鲁棒性」、「2021 CCF BDCI千言:问题匹配鲁棒性评测」等,累计赛事报名人数5178,累计数据集下载次数9616,结果提交次数12793。
主要技术特点:
LCSTS是目前最大的、百万级开放式中文短文本摘要数据库,支持生成式短文本摘要的研发、文本生成研发等;
LCQMC是目前最大的中文通用领域意图匹配语料库,标注的匹配对本身是通过语义匹配模型进行筛选的,因此对模型来说具有较大的挑战性,能够有效增强意图匹配模型性能;
BQ数据库是金融领域目前开放出来的最大的中文意图匹配语料库之一,原始数据来源于大规模真实自动客服系统,具有很强的真实性与挑战性。
应用范围:
中文的自动文摘、自动客服、语义匹配、信息检索、文本生成等技术和行业应用所涉及到的领域。
照片资料:
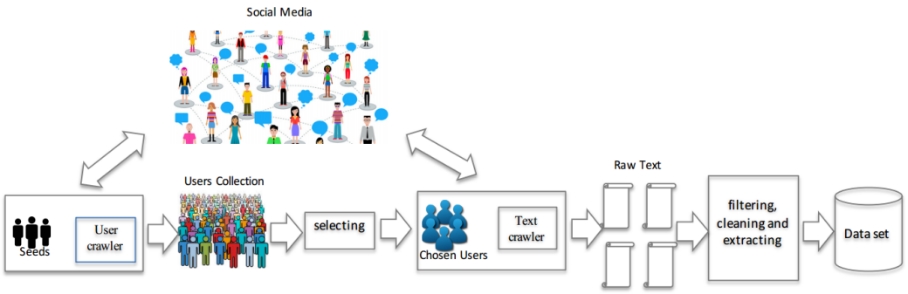
图片1 LCSTS构建过程

图片2 LCQMC构建过程

图片3 LCSTS部分申请机构

图片4 该成果荣获 2018年深圳市科技进步奖二等奖